Published 21. March 2023 by Kevin Nørby Andersen
5 min read — Link to this post
I’ve been curious about how we get AI tools to work for us while we’re not working. So I built a factory to work on my ideas, when I’m not working.
Link: idea factory prototype
While I get tremendous inspiration and productivity out of tools like (Chat)GPT, Stable Diffusion, etc., the limitation is I constantly have to breathe life into them, and along with it, spend my entire attention.
Just like we are spending time on our phones that we used to spend on other things (do we even remember anymore?), we now spend time with AI tools, that just a year or two ago didn’t exist. Is that the best use of our time? Besides, it feels reductive that we aren’t taking advantage of the fact these tools can work while we don’t.
But what if we could have it all, and get AI to work when we’re not working? The inspiration for the prototype is this concept of ‘asynchronous AI’ - using generative AI tools, without taking too much time and attention out of our day.
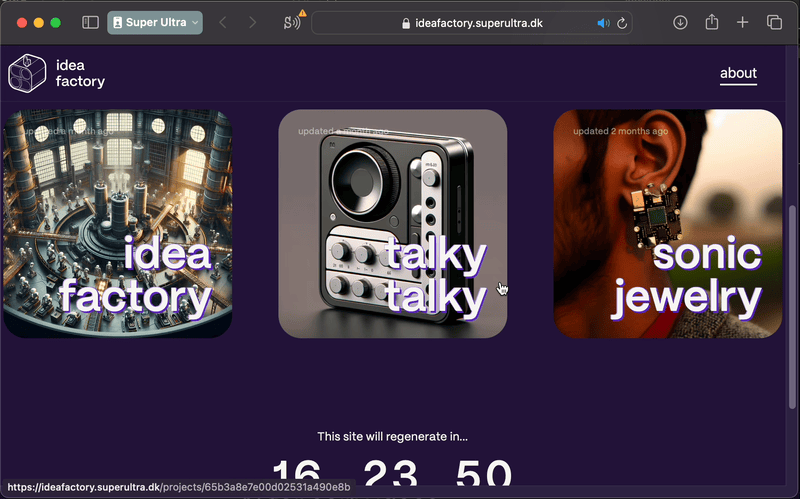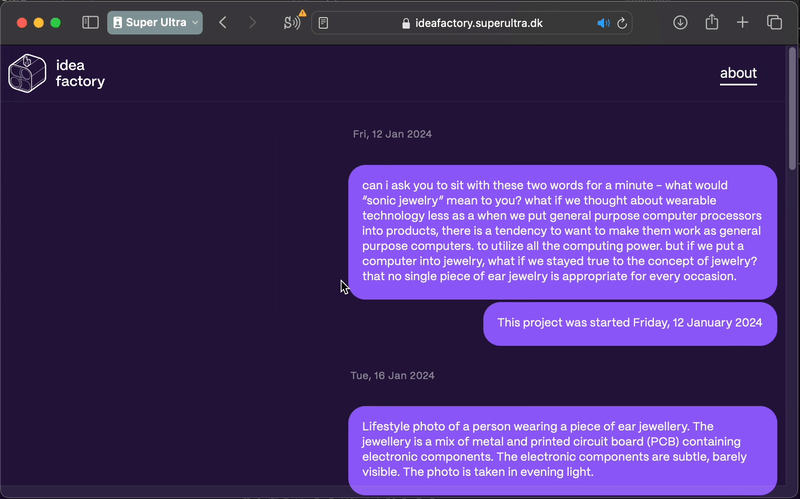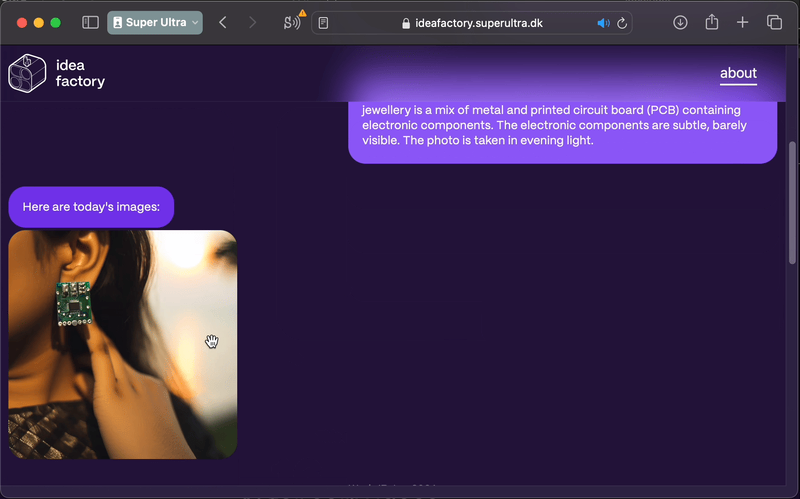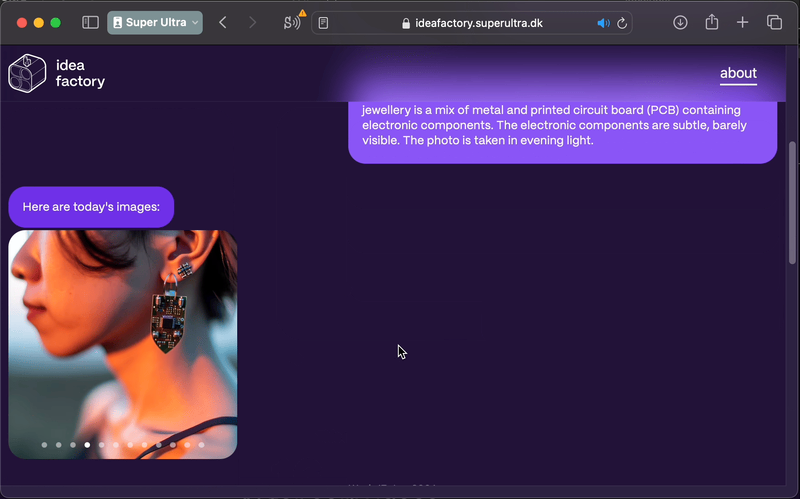
This first iteration is really just an image factory, since it’s limited to text-to-image generation, but I’m hoping to extend the factory over time.
Idea Factory consists of two parts: a bot, for image generation and uploading, and a website, for displaying projects, prompts, and images.
Between the two, a shared database and cloud storage is used to store and retrieve project data and images.
In the database, there are three collections: projects, images and prompts. On the website, they’re displayed in a messaging-style interface.

Image bot is a Node.js script that runs on a schedule. Between 6pm and midnight, it is triggered every 30 minutes. Every time it is triggered, it scans the project database. For each active project, it generates an image based on the latest project prompt. It uses OpenAI’s DALL-E-3 image generation model.
Factory website is a SvelteKit app that rebuilds every day at 7am. It fetches the latest images from the shared cloud storage and displays them in a grid. For each project, images are displayed in an Instagram-style carousel, grouped by day.
My experience using the prototype has been mixed. In one way, it was great to wake up every morning to new work. In a way, it felt like coming into a morning meeting with a team and having work presented. It felt like I had less to lose, only needing to load up a website and having the work presented to me.
The quality of the images vary a lot. Some are useful and inspiring, a lot feel repetitive, and some even feel ridiculous.

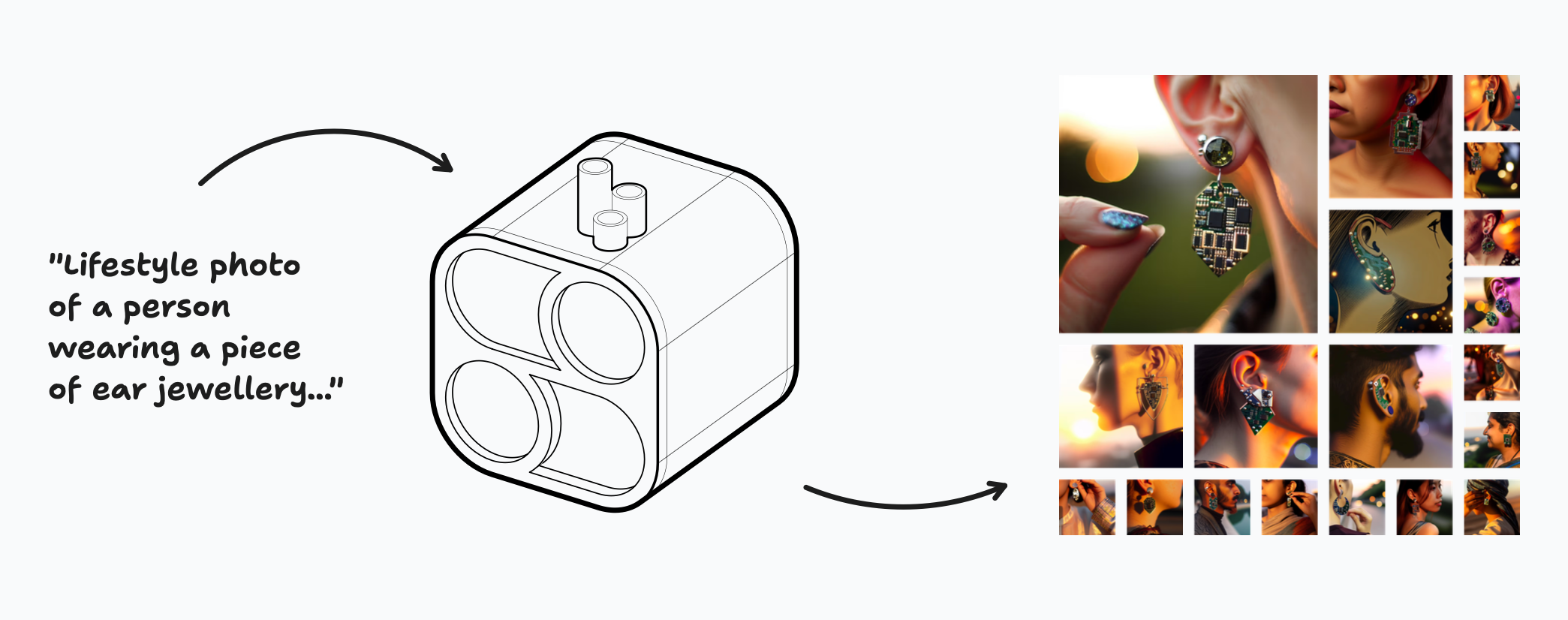
One of the highlights was for the Sonic Jewelry project. The project is around a piece of jewelry that uses machine learning to listen to your environment, records and maybe reacts to certain words like “hi” or “thanks”. In some way, becoming an auditory diary (will write more about this project later). My own sketches have been simple small devices that would hang from a regular earring, but the images above inspired me to think about other ways that the device could sit in the ear, or maybe even have some sort of frame around it.
But overall, I was hoping for more from this prototype. Things that felt limiting:
No “inpainting”, meaning it is not possible to paint over the generated images to make specific edits like “change that shape”
The DALL-E-3 API doesn’t return the unique ID of the generated image to be referenced later on. E.g. “Generate an image like
IDbut in the style of line art”The API does not take an image as input, so all prompts have to be written
Some of these limitations might be overcome by switching to other models like Stable Diffusion or Midjourney, while others would need to be built.
I think a tool like this could become powerful if there were better ways to interact with the image generation and more clever ways of using text generation to improve the prompts. Here are some ideas
It would be great to have the ability to render multiple images on a larger canvas in the style of moodboards. Think Pinterest boards.
It should be possible to chain the image generation with text generation. For example, “a piece of electronic jewelry” as a prompt could be deconstructed into nouns and verbs and extended with different adjectives that would then turn into new prompts.
Enable the ability to select image and mark them “more like this”/”less like that”, and use that as input for the next round of image generation
Rather than prompting using text, using image input. This is a technique already available in many image generation models
Every image should have a unique ID that can be used to reference it in the future. Example: “Remember 9808458973? Generate something like that, but with a nice sunset behind it”
Use something like TLDraw as an editor inside the factory interface, to enable painting, instead of having to manipulate images outside.
If you liked this post, please consider sharing it. Here is the link.